Here’s the fact – gRPC does not work with AWS load balancers properly.
How does load balancer work?
Some time ago, we worked on an ambitious project — SubbXi. It’s a web platform for captioning movies. We decided to build micro services architecture & use gRPC for communication.
In short, gRPC is an excellent, performance-oriented framework. It’s built over the protocol HTTP 2.0, which means that the TCP connection between servers will be set up just once.
It will exist for approximately 176K seconds (which is a lot!). Naturally, all the following requests/responses will use the same connection, which is amazingly faster & more convenient.
If you have lots of traffic — gRPC ultimately wins the day (in comparison with REST).
But little did we know that AWS actually don’t support HTTP 2/0. So, let’s get to the root of the problem.
 gRPC Tutorial
gRPC Tutorial
AWS Load Balancers | Elastic Load Balancer
There are 3 types of load balancers on AWS: Application Load Balancers (Layer 7 Load Balancer), Network Load Balancer (Layer 4), Classic Load Balancer. In this article, we’ll review how AWS work with Application and Network Load balancers. We will skip AWS classic load balancer, since it’s pretty old-school. So, let’s have a more detailed & practical look on AWS load balancing. Let’s proceed to our Layer 4 vs Layer 7 load balancing brief comparison.
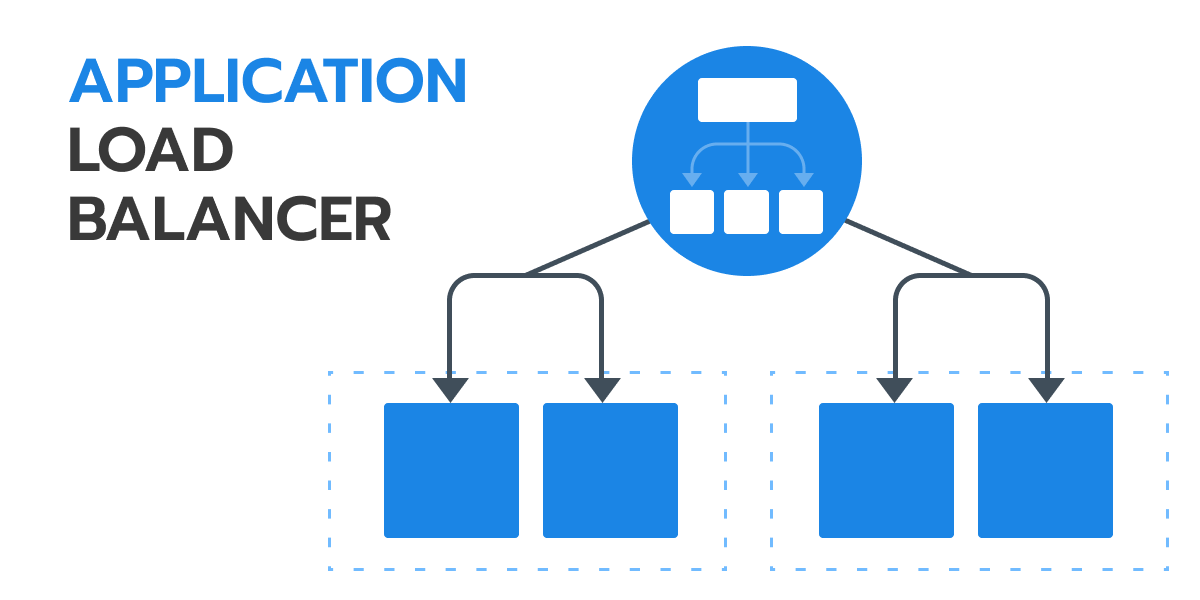
Application load balancer (Layer 7 Load Balancer)
How does this load balancer work? Application load balancer works seamlessly with SSL protocols, which is super convenient. However, it partially supports HTTP 2.0. If this load balancer receives HTTP 2.0 request, it’s going to return HTTP 1.1… which ultimately defeats the purpose.
The possible solution here is to create ‘a middleman’ between your server and your load balancer. Its main goal here is to ‘convert http 1.1 requests into http 2.0. But how viable is this option?
It’s not the most ‘neat’ solution, but it works. It’s more like a temporary substitute instead of solving the problem completely. Frequently, the connection will get destroyed and created again. The HTTP 2.0 request will get converted into HTTP 1.1 and then again into HTTP 2.0. which results in a tiny delay. It’s not significant, but it’s still there.
 Application load balancer
Application load balancer
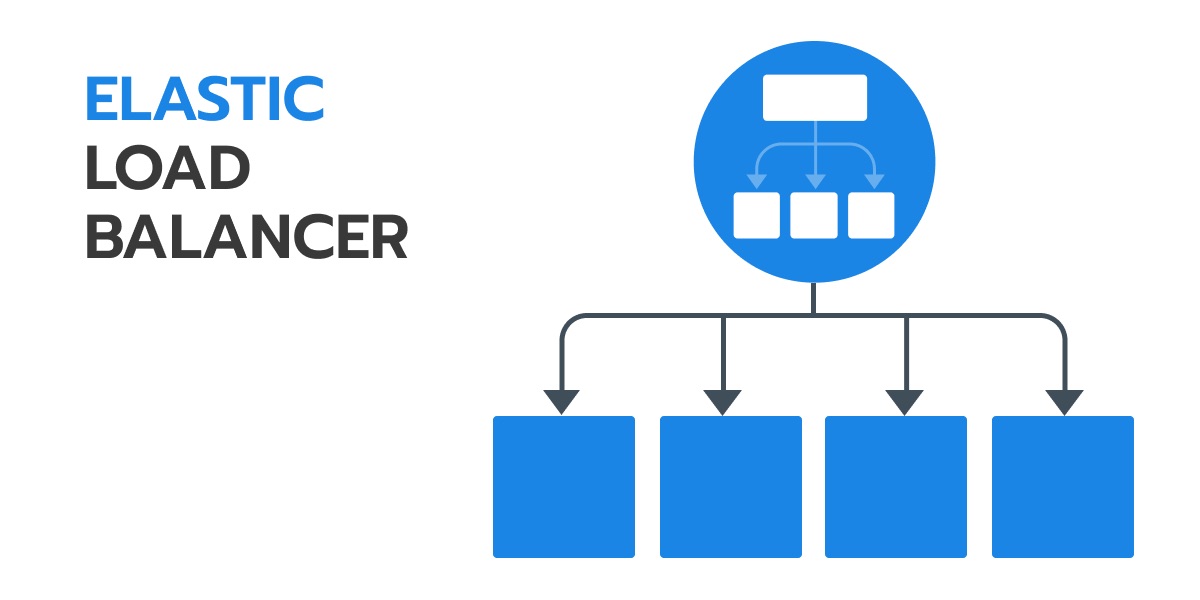
Network Load Balancer (Layer 4)
Network Load Balancer can’t really differentiate between http 1.1 and http 2.0 requests. It would simply send all requests to your server instance. So what’s the problem, in this case? Well, this load balancer will send all of the requests to the single server instance. Let me repeat this — same instance. As a result, there’s no load balancing, in the first place.
At first, this is what we’ve done with one of our cases — SubbXi. Eventually, we noticed that all requests are sent to the same server instance. The second server instance will launch since there’s a huge load on the first one, but it’s not going to function.
Meanwhile, it will receive only new requests, while the old ones will be ‘killing’ the first instance. If the third instance will launch it will only receive the requests created after it was launched.
 Elastic load balancer
Elastic load balancer
How Can you Load Balance gRPC on AWS using Envoy
So what’s the solution here? We decided to use third-party software for load balancing. In this case, we used Envoy (for AWS load balancer Layer 7). It’s an open-source software created by Lyft.
So why Envoy? First off, it’s lightweight comparing to NGINX, Linkerd and HAProxy. It’s also easy to incorporate into microservices architecture. Because it’s written in C++11, it wins over Linkerd that’s built on Java.
First off we used our standard Frontend Envoy load balancer. There are another load balancers called sidecars. Each of them is placed just near each instance of service. These are also Envoys but they have different configuration. They work with the server specifically and they are also connected between each other.
Therefore frontend load balancer always has a connection and even if it doesn’t — it can create it. So when it receives a request, he directs it to whatever sidecar or a server instance it feels fit. Usually it simply directs them using a ‘circle’ balancing the load.
How to Solve the Problem using Fulcrum mini-setup | gRPC Tutorial
So I created a mini-setup to illustrate the solution better. It’s strikingly simple. It’s a single service that processes just one echo-request and its number. All the data will be then available in logs. You can download it on Fucrum Github.
The setup includes:
- A simple service
- Frontend Proxy
- Sidecar Envoy
- docker.compose
We also created configurations for Envoy sidecars and frontend proxy. As for the Envoy sidecars, you can also pre-define the desired service address and ports. It’s a simple setup, but it illustrates the process better.
There’s also a small playground, meaning you can download the file and try for yourself.
There’s also a docker file that launches 2 services. Each of them starts their own sidecar + a single frontend proxy. That makes up 5 services.
How does this work?
You can see all requests in logs after you launch the playground. There’s also a tiny utility jpURL — software that helps you process requests with gRPC.
You can send requests from your local computer to the pre-defined port. In logs you will immediately see your request: ‘service-1 processed your request’. If you send a few more echo-requests you will see that it will be sent to different services. Envoy is going to balance the load by sending them to both services. Wohoo!
How to Set up Frontend Proxy
In Frontend proxy, you should define the desired port and HTTP 2.0 protocol. Let’s break down each line below:
Line 3
The third line pre-defines TCP connections. It’s configured using the variables of the environment (see below).
static_resources:
listeners:
- address:
socket_address:
address: 0.0.0.0
port_value: $LISTEN_PORT
Line 11–13
Afterward, you need to configure protocol settings. That’s exactly where you define HTTP 2.0 for your Envoy sidecars.
config:
codec_type: http2
stat_prefix: ingress_grpc
http2_protocol_options: {}
Lines 21–23
In the lines 21–32 you configure gRPC framework. All paths used for processing TCP connections have to use gRPC.
routes:
- match:
prefix: '/'
grpc: {}
Line 26–28
We finally reached the fun part. When working at SubXXI, this took us a few days to learn.
We faced the following problem: users were trying to download a movie, but the downloads failed after just 15 seconds. What happened here?
According to Envoy default settings, requests can be processed up to 15 seconds, tops. This means that if after 15 seconds backend doesn’t send any response to the request, the request will simply disappear. You will see a ‘Request Timeout’ message.
If you configure the settings like in the example below — you will eliminate timeout completely.
timeout:
seconds: 0
nanos: 0
http_filters:
- name: envoy.router
config: {}
Lines 36
Frontend Proxy re-directs the requests. Here you configure how requests are sent to services. In the line 36 we pre-defined ‘round-robin’ model (the requests are directed in a circle model).
lb_policy: round_robin
Lines 40–41
Lines 40–41 define where the requests will be sent.
- socket_address:
address: $SERVICE_DISCOVERY_ADDRESS
port_value: $SERVICE_DISCOVERY_PORT
So when the service is launched, we set the service discovery address & the desired port for the sidecar Envoy.
Let’s say you have 3 services. Initially, the problem is that each of them has the same host (e.g. service.internal). However, when Frontend Proxy makes DNS requests, it receives three different IP addresses.
The Frontend Proxy then understands that requests can be instantly processed by 3 different services. It will choose one of them thus balancing the load, cool!
This process is ongoing. Frontend Proxy is constantly checking the local host. If DNS returns an unknown IP address, this means a new instance is up. In that case, Frontend Proxy registers the new address and understands that it can process new requests.
In case, if DNS doesn’t return an ‘older’ iP address, this means something is wrong. Therefore, Frontend Proxy is not going to send requests to this particular service instance. Which ultimately means — there’s no traffic loss.
This is pretty convenient to use on ECS, because of their service discovery. So when you set up a service on ECS, you can set the host. This host will then be used for returning IPs.
How to Configure Sidecars
Their configurations are similar to Frontend Proxy, except for the line 36. This line configures ‘round-robin’ model, which is simply not needed for sidecar Envoy. It’s obvious, since the requests will be always sent to the service nearby.
Because the playground is working through the docker.compose, we can’t launch the sidecar and service at the same time. They will be started separately.
So when we set up the service on ECS, we need to accurately describe containers in the task definition. Basically, we need to pre-define that service address equals local host. As a result, sidecar and the service will launch next to each other and set up the connection between each other.
Bottom Line: gRPC Tutorial
That’s basically it. We hope you enjoyed the article and it helpd you set up load balacing for gRPC.If you encounter any questions regarding other parameters, check out Envoy documentation.

gRPC Tutorial FAQ
-
What is gRPC protocol?gRPC is an acronym that stands for a remote procedure call and refers to an open-source framework developed by Google back in 2015. The framework can run anywhere and allows front-end and back-end apps to interact transparently, as well as facilitating the process of building connected systems. gRPC is commonly used for distributed systems, mobile-cloud computing, efficient protocol design flow, microservices, etc.
-
How to get gRPC to work with Unity?gRPC has recently got an experimental package for Unity so that it can now work with the game engine. This precise yet informative instruction is prepared to illustrate the process and help you get the remote procedure call system to work with Unity.
-
Is gRPC better than REST?While testing these two methods based on a specially created benchmark application, gRPC happened to be faster than REST in almost all cases. REST showed better results only when the transmitted data was very small and multiple clients were making a server call at one time. Because of the protocol buffer used for data serialization, gRPC provides faster, smaller, and simpler payloads. Other than that, it is known for use of binary data that is supposed to make communication compact and efficient. That is why gRPC is a number-one choice for building iOS and Android mobile apps.







